在人工智能的浪潮中,卷积神经网络(CNN)无疑是计算机视觉领域的基石技术之一。作为一名喜欢在技术领域“打酱油”但深度关注底层演进的老鸟,我深感从经典的LeNet到现代的EfficientNet,这不仅仅是网络层数的堆叠或参数量的增加,更是一场关于模型架构、计算效率与泛化能力的深刻革命。本文旨在梳理这一发展脉络,并探讨其对人工智能基础软件开发带来的启示。
1. 开山鼻祖:LeNet-5(1998)
LeNet-5由Yann LeCun等人提出,是第一个成功应用于手写数字识别的CNN。其结构简洁明了:卷积层、池化层、全连接层的顺序堆叠,确立了CNN的基本范式——局部连接、权值共享和下采样。它虽然小巧,但证明了通过卷积自动提取分层特征的有效性,为后续研究指明了方向。在软件开发中,LeNet的实现往往是初学者理解CNN运作原理的最佳起点。
2. 深度崛起:AlexNet(2012)与VGGNet(2014)
AlexNet在ImageNet竞赛中一战成名,真正点燃了深度学习的热潮。它引入了ReLU激活函数、Dropout正则化和GPU加速训练等关键技术,证明了深度(8层)网络强大的表征能力。紧随其后的VGGNet则通过反复堆叠3x3的小卷积核,构建了16-19层的均匀网络,强调了“深度”的重要性。这一时期,基础软件开发开始面临挑战:如何高效管理更深的网络、利用并行计算资源以及防止过拟合。框架如Caffe、TensorFlow的兴起,正是为了应对这些复杂性。
3. 结构创新:Inception(GoogLeNet,2014)与ResNet(2015)
随着网络加深,模型退化(并非过拟合导致的性能饱和)和计算成本成为瓶颈。GoogLeNet的Inception模块通过并行使用不同尺寸的卷积核(1x1, 3x3, 5x5)和池化,在增加网络宽度的同时控制了参数量,其核心思想是“密集计算结构替代稀疏结构”。而ResNet的革命性在于提出了残差学习,通过快捷连接(shortcut)实现了超深度网络(如152层)的成功训练,解决了梯度消失/爆炸问题,使“深度”几乎不再受限。这两者标志着CNN设计从简单的堆叠转向了精心设计的模块化架构。对软件开发而言,这意味着需要支持更灵活的网络拓扑和复杂的层间连接。
4. 轻量化与自动化:MobileNet(2017)与EfficientNet(2019)
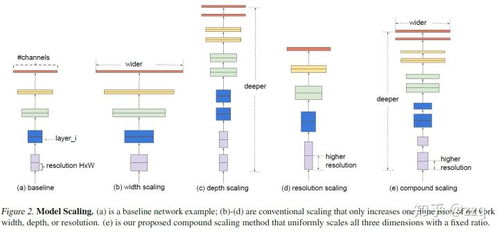
将CNN部署到移动端和嵌入式设备催生了轻量化模型的需求。MobileNet系列利用深度可分离卷积大幅降低了计算量和参数量,在精度和效率间取得了出色平衡。而EfficientNet则将架构搜索推向了新高度。它系统地研究了网络宽度(channel数)、深度(层数)和分辨率(输入图像尺寸)的缩放关系,并提出复合缩放方法,使用神经架构搜索(NAS)找到了最优的缩放系数基线模型(B0-B7)。EfficientNet在同等计算资源下,实现了前所未有的精度提升,代表了当前CNN在精度-效率权衡上的前沿。
对人工智能基础软件开发的启示
作为“打酱油的老鸟”,我观察这一演进过程,对软件开发有几点深刻体会:
- 抽象与模块化:从LeNet的硬编码到Inception/ResNet的模块化设计,软件框架必须提供高级API,让开发者能像搭积木一样构建复杂网络。
- 计算图优化:随着结构变得复杂(如残差连接),框架后端需要强大的计算图优化能力,以实现高效的内存利用和算子融合。
- 硬件协同:从AlexNet的GPU加速到MobileNet的移动端部署,软件栈必须考虑跨平台、跨硬件的性能移植,支持专用加速器(如NPU)。
- 自动化工具集成:EfficientNet的成功离不开NAS。未来的开发平台可能需要将架构搜索、超参调优等自动化工具无缝集成到工作流中,降低专家门槛。
- 从研究到生产的管道:模型演进速度极快,软件需要支持从原型(研究)到部署(生产)的平滑过渡,包括模型压缩、量化和转换工具。
****
从LeNet到EfficientNet,CNN的发展是一部追求“更优性能”与“更高效率”的编年史。它不仅是学术思想的碰撞,也深刻驱动着人工智能基础软件的革新。对于开发者和研究者而言,理解这条脉络,不仅能更好地应用现有模型,更能洞察下一个可能的技术突破点。在这个过程中,即使是“打酱油”,也能在关注底层演进中,为构建更强大、更易用的AI工具链贡献一份力量。